Architecture (AS IS)
1. Given Architecture
1.1 Context
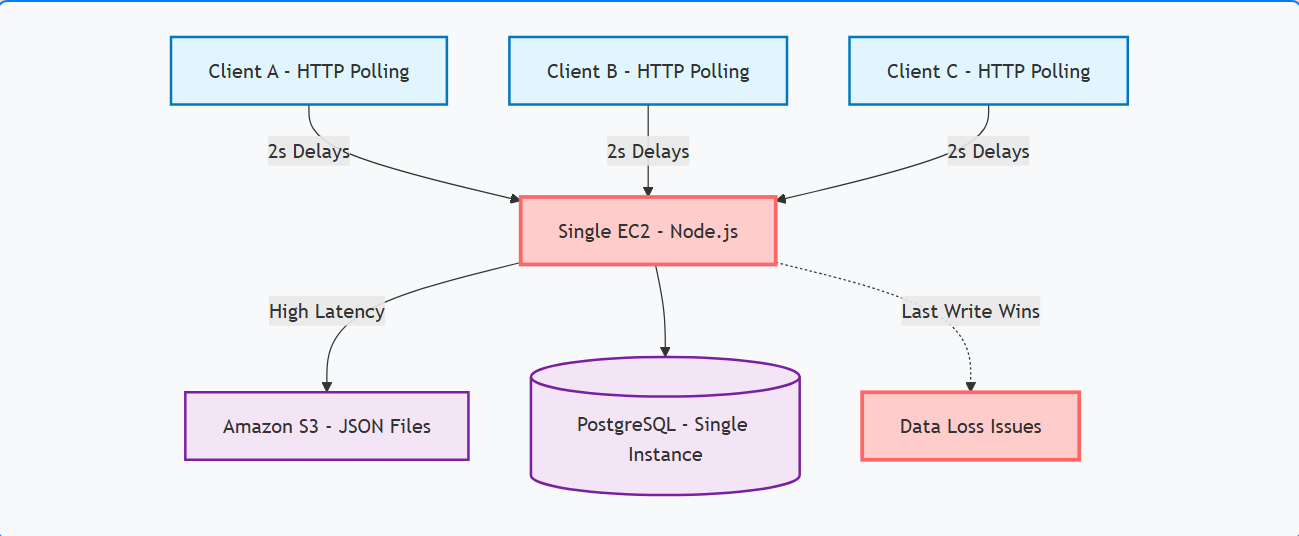
This is an architecture design for a Document Collaborative Editing online that supports also offline edits and merges conflicts automatically, simillar to Google Docs. This system should support 100k+ simultaneous users and provide sub-200ms latency operations, it also needs to be deployed and distributed globally.
1.2 AS IS diagram
Simple AWS-based monolithic solution.
2. Analysis
2.1 Security and compliance
- The current flow doesn't have authentication and authorization layers to ensure security.
- Open ID Connect (OIDC) instead of JWT authentication should provide a better authentication and authorization process.
- By adopting an OIDC approach, we delegate login to a trusted Identity Provider (IdP) and reduces risks from implementing custom authentication.
- No in-flight and at rest encryption.
- No network configurations to establish secure connections between components when exposing services to the clients.
- No IAM service roles or policies configuration mentioned.
- No firewall configuration mentioned.
- No protection against common attacks such as DDoS, XSS, SQL Injection and so on.
2.2 Data loss with Last Write Wins (LWW) strategy
- LWW is not the ideal approach to handle concurrent edits in a collaborative document editor.
- LSEQ algorithm should be a better solution to ensure sequential, ordered and idempotent operations, optimizing the data structure to support more unique IDs and bigger documents.
2.3 Single point of failure with single instances
2.3.1 Single EC2 instance
- Recommended to use horizontal scaling with AWS Autoscaling Group to ensure scalability during peak collaboration periods without the overhead to manually manage all the instances.
2.3.2 Single PostgreSQL instance
- All data relies on one PostgreSQL instance.
- If the database goes down, the entire system becomes unavailable.
- Any hardware, network, or maintenance issue impacts all users, creating a critical risk.
2.3.3 No scalability (Single instances)
- Backend and database are single instances only.
- Cannot scale horizontally to handle large numbers of concurrent users.
- High user load or many simultaneous edits may lead to increased latency or system crashes.
2.4 HTTP polling: Inefficient network strategy
- Clients rely on periodic HTTP requests to get updates.
- Generates unnecessary network traffic and adds noticeable latency.
- Leads to slower user experience and higher CPU/network usage on the server.
- Bad user experience caused by the unecessary latency.
- Is recommended to use another approach to optimize latency and user experience, such as websockets, GraphQL subscriptions or server-sent events.
2.5 Availability and resilience: Not fault tolerant
2.5.1 No backups
- No backup strategy was mentioned for the database and also the file management.
2.5.2 Single region deployment
- No backup strategy was mentioned for the database and also the file management.
- No replication or failover mechanisms exist.
- Any instance failure or network issue can bring the service down completely.
- Lack of continuous availability is a major problem for a real-time collaborative system.
2.6 Monolithic approach
2.6.1 Unable to scale services individually
- All backend services are tightly coupled or deployed as single instances.
- You cannot scale specific components (sync service, API service, or persistence) independently based on load.
- High traffic in one service affects the entire system, causing bottlenecks and potential slowdowns.
- Limits flexibility for horizontal scaling and makes resource allocation inefficient.
2.6.2 Tightly coupled solution
- Recommended to use message brokers to decouple services and layers and enable a better performant asynchronous workflow and increase scalability and resilience.
2.7 Observability
- No centralized observability stack is configured.
- No metrics collection or monitoring solution in place.
- No distributed tracing implemented to track request flows.
- No alerting or alarm mechanisms configured for incident detection.
2.8 AWS S3: File management
- Recommended to use multipart uploads/downloads to stream large files and optimize PUT and GET operations.
- Recommended to use partitions to store files more efficiently.
2.9 No cache strategies
- Recommended to use cache strategies with Redis to optimize performance and reduce database overhead for some operations that could support cache, per example the authentication middleware to store user session information.